















{kind=link}
Podcasts
Watch videos featuring supply chain experts








Supply chain management involves the orchestration of various processes, from procurement to production and distribution, to ensure that products reach consumers efficiently. In recent years, the integration of cutting-edge technologies has played a pivotal role in enhancing supply chain operations. One such technology that holds great promise is the use of vector databases.
Vector databases are specialised databases designed to handle vector data efficiently. They excel in storing, indexing, and querying high-dimensional data, making them suitable for a wide range of applications, including supply chain management. In this article, we will explore the use cases of vector databases in the supply chain and can do a practical implementation in Python using the Faiss library.
Faiss library: Faiss is a high-performance library for efficient similarity search and clustering of dense vectors. Let's explore a simple implementation example using Faiss for product similarity analysis in a supply chain context.
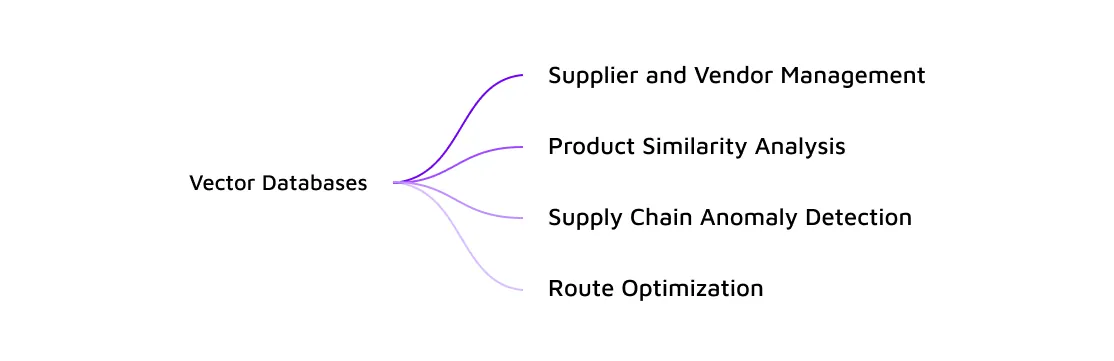
Vector databases can be used to analyse product similarities based on various features such as size, weight, and composition. By representing products as vectors in a high-dimensional space, similarity searches become fast and efficient. This enables supply chain managers to identify similar products, aiding in demand forecasting, inventory optimization, and supplier selection.
Product Similarity Analysis using vector databases is a powerful tool not only for identifying similarities but also for uncovering nuanced differences among products. While the primary focus is on finding products with similar characteristics, the inherent nature of vector representations allows for a comprehensive understanding of both similarities and distinctions.
For logistics and distribution in the supply chain, vector databases can assist in route optimization. Location vectors can represent warehouses, distribution centres, and delivery points. By calculating distances and travel times efficiently, supply chain managers can optimise delivery routes, minimise transportation costs, and improve overall logistics efficiency.
Requirement: Integrate real-time data feeds to update vector databases promptly.
Logic: By incorporating live information on traffic, road closures, and weather conditions, the system can dynamically adjust routes for maximum efficiency.
Prioritisation of Deliveries: Thus, Allowing for prioritisation of deliveries based on urgency and importance. Logic: Ensuring that critical deliveries are prioritised can enhance customer satisfaction and meet service level agreements.
Vector databases are powerful tools for detecting anomalies in the supply chain. By representing normal behaviour as vectors, any deviations from the expected patterns can be easily identified. This is particularly useful in monitoring the flow of goods, identifying potential disruptions, and preventing issues such as theft or product spoilage.
Vector databases can streamline the process of evaluating and managing suppliers. Vendors and suppliers can be represented as vectors based on various criteria such as reliability, lead times, and quality. Supply chain managers can then perform similarity searches to identify the most suitable suppliers for specific requirements.
Vector embeddings are numerical representations of objects, words, or concepts in a multi-dimensional space. They are used in various applications such as natural language processing, image recognition, and recommendation systems. Here are some general life examples to illustrate the concept of vector embeddings:
Example: Consider the word "king." In a word embedding space, the vector representation of "king" might be [0.4, 0.7, -0.2], while "queen" could be represented as [0.5, 0.7, -0.1]. The vector captures semantic relationships, and the similarity between these vectors reflects the similarity between the words.
Example: Suppose you are shopping online, and the website uses vector embeddings for products. If you often buy running shoes and sports apparel together, the vectors representing these items would be closer in the embedding space. The system can then recommend sports apparel when you view running shoes.
Vector databases work by representing data as vectors in a high-dimensional space and then employing indexing structures and algorithms to efficiently store, search, and retrieve similar vectors. To illustrate how vector databases work, let's walk through a simple mathematical example using two-dimensional vectors.
Example: Similarity Search in a 2D Vector Database Suppose we have a dataset of 2D vectors representing points in a Cartesian plane:

Now, let's consider a query vector:

Step 2: Ranking by Similarity We rank the vectors in the dataset based on their distances from the query vector. Smaller distances indicate greater similarity.
Step 1: Distance Calculation One common measure of similarity is the Euclidean distance between vectors. The Euclidean distance between two vectors u and v in a two-dimensional space is given by:
Step 2: Ranking by Similarity We rank the vectors in the dataset based on their distances from the query vector. Smaller distances indicate greater similarity.

Step 3: Retrieval
The vector database retrieves the top-k vectors based on similarity. For example, if we want the top 2 similar vectors, we retrieve vectors A and B.
Description: Faiss (Facebook AI Similarity Search) is an open-source library developed by Facebook Research for efficient similarity search and clustering of dense vectors.
Supports a variety of indexing methods, including flat, IVF (Inverted File), and HNSW (Hierarchical Navigable Small World). Optimised for both CPU and GPU. Provides support for large-scale datasets and real-time searches.
Description: Milvus is an open-source vector database designed for similarity search and analytics. It is developed by Zilliz, an AI company focused on providing solutions for vector data management.
Supports vector indexing and searching for applications like image and video retrieval, recommendation systems, and more. Scalable and efficient, enabling the handling of large-scale vector datasets. Provides support for both CPU and GPU acceleration.
Atlas Vector Search is a transformative tool that empowers users to explore unstructured data with unparalleled efficiency. By leveraging vector embeddings generated through machine learning models such as OpenAI and Hugging Face, Atlas Vector Search opens the door to a myriad of use cases, offering a versatile solution for diverse applications. Here are some key use cases that showcase the potential of Atlas Vector Search:
Atlas Vector Search enables advanced retrieval augmented generation, allowing users to retrieve relevant information from unstructured data and use it to enhance content generation. This is particularly valuable in natural language processing tasks, where the system can pull in contextually relevant information to improve the quality of generated content.


